Link to paper
The full paper is available here.
You can also find the paper on PapersWithCode here.
Abstract
- Introducing a new collection of spoken English audio for training speech recognition systems
- Audio is derived from open-source audio books from the LibriVox project
- Contains over 60K hours of audio, largest freely-available corpus of speech
- Audio segmented using voice activity detection and tagged with SNR, speaker ID and genre descriptions
- Baseline systems and evaluation metrics for 3 settings: zero resource/unsupervised, semi-supervised, distant supervision
- Evaluated on standard LibriSpeech dev and test sets
Paper Content
Introduction
- Automatic Speech Recognition (ASR) has made progress in recent years with deep neural networks and large datasets
- Costs of annotating larger datasets are prohibitive
- Interest in weakly supervised solutions with fewer human annotations
- Semi-supervised setting: fraction of dataset labelled, rest unlabelled
- Distant supervision setting: dataset mostly or entirely unlabelled, but large quantities of unaligned text
- Pretraining with labels from other languages or unsupervised objectives
- Zero resource ASR discovers its own units from raw speech
- Libri-light: open-source corpus of unlabelled speech and common set of metrics to evaluate three settings
- Test sets identical to LibriSpeech to compare weakly supervised results with state-of-the art
- Baseline system and datasets open source
Related work
- Open source software and datasets facilitate machine learning progress
- LibriSpeech is a large open-source dataset with audio books and sentence-level annotations
- CommonVoice project contains 2900 hours of read speech in 37 languages
- Wilderness dataset contains text of Bible read in 750 languages
- Zero Resource Challenge has released datasets and metrics for unsupervised setting
- IARPA Babel program has initiated push towards limited supervision for less studied languages
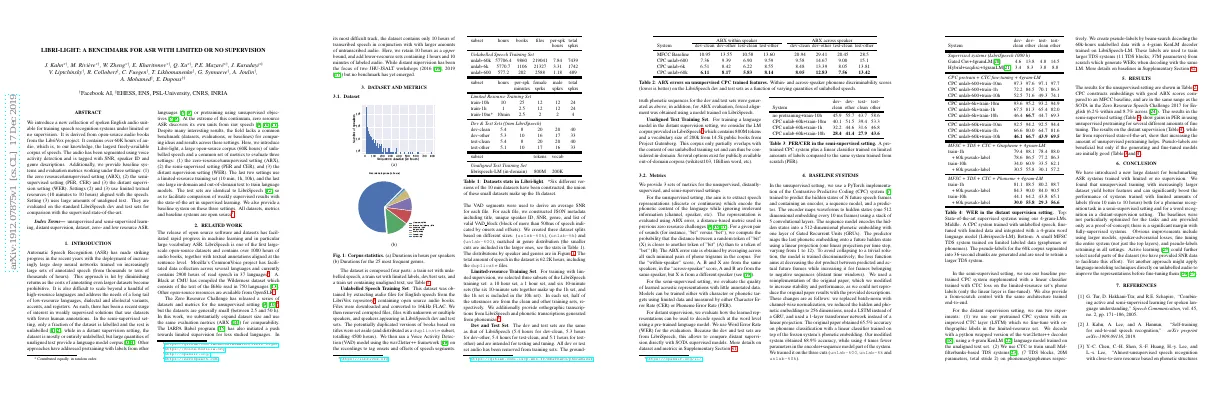
- Dataset contains 10 hours of transcribed speech and larger amounts of untranscribed audio
- Dataset contains 4 parts: unlabelled speech, limited labels, dev/test sets, and unaligned text
- Unlabelled Speech Training Set obtained from LibriVox repository
- Dataset splits based on different sizes: unlab-60k, unlab-6k, unlab-600
Limited-resource training set.
- Selected 3 subsets of LibriSpeech training set: 10 hour, 1 hour, and 6 10-minute sets
- Half of utterances from clean and other training sets
- Orthographic and phonetic transcriptions from LibriSpeech
- Dev and test sets same as LibriSpeech
- LM corpus provided in LibriSpeech with 800M tokens and 200k vocabulary size
Metrics
- Aim of unsupervised setting is to extract speech representations that encode phonetic content while ignoring irrelevant information
- Unsupervised setting evaluated using ABX error, a distance-based metric
- For semi-supervised setting, quality of learned acoustic representations evaluated with little annotated data
- Distant supervision evaluated by Word Error Rate (WER)
Baseline systems
- PyTorch implementation of Contrastive Predictive Coding (CPC) system used to predict hidden states of future speech frames
- Encoder maps waveforms to hidden states using 5 convolutional layers
- Sequence model encodes hidden states into 512-dimensional phonetic embedding with one layer of Gated Recurrent Units (GRUs)
- Predictor maps last phonetic embedding onto future hidden state using linear projection
- Model trained discriminatively to avoid trivial solution
- Original paper obtained 65.5% accuracy on phoneme classification
- Modified system obtained 68.9% accuracy with 4 times fewer parameters
- Semi-supervised setting uses baseline pretrained CPC system with linear classifier trained with CTC loss
- Distant supervision setting uses pretrained CPC system with improved CTC layer and pseudo-labels generated by beam-search decoding
Results
- Table 2 shows that CPC embeddings have good ABX scores compared to an MFCC baseline.
- Results in the semi-supervised setting (Table 3) show gains in PER when using unsupervised pretraining.
- Results on distant supervision (Table 4) show that increasing the amount of unsupervised pretraining helps.
Conclusion
- Introduced a new large dataset for benchmarking ASR systems
- Unsupervised training with larger dataset yields better features
- Performance of systems trained with limited labels (10 min to 10 hours) improved
- Baselines provided as proof-of-concept, significant margin with fully-supervised systems
- Improvements include larger models, speaker-adversarial losses, fine tuning entire system, pseudo-labels retraining
- Active learning could select useful parts of dataset
- Language modeling techniques applied on unlabelled audio to improve representations
- Dataset constructed with data download, exclusion of bad files, conversion to flac, extraction of VAD, SNR, and Perplexity
- Voice Activity Detection accomplished using TDS acoustic model
- SNR ratio calculated using VAD labels
- JSON files constructed with metadata, SNR, perplexity, macro-genre tags, VAD information
- Files split into cuts of different sizes
- ABX task used to quantify property of features coding for same phonemes
- Unsupervised feature model trained using Contrastive Predictive Coding algorithm
- TDS model used for VAD has 100 million parameters
- TDS model used for training has 20 million parameters
- Training took approximatly two days on NVIDIA Tesla V100-SXM2-16GB
- Training data limited, smaller TDS model used
- Model optimized with plain SGD with momentum