Link to paper
The full paper is available here.
You can also find the paper on PapersWithCode here.
Abstract
- Advances in computer vision and machine learning have led to development in 2D and 3D human pose estimation.
- Human pose estimation from images is affected by occlusion and lighting.
- Radar and LiDAR technologies need specialized hardware that is expensive and power-intensive.
- Recent research has explored the use of WiFi antennas for body segmentation and key-point body detection.
- This paper further expands on the use of WiFi signal and deep learning to estimate dense human pose correspondence.
- Results of the study show that the model can estimate the dense pose of multiple subjects with comparable performance to image-based approaches.
- This paves the way for low-cost, broadly accessible, and privacy-preserving algorithms for human sensing.
Paper Content
Introduction
- Progress has been made in human pose estimation using 2D and 3D sensors
- LiDAR and radar sensors are expensive and power-consuming
- RGB cameras have narrow field of view and poor lighting conditions
- Privacy concerns prevent use of cameras in non-public places
- WiFi signals can be used as a substitute for RGB images in certain instances
Related work
- Computer vision research has focused on dense pose estimation from images and video
- Güler et al. mapped human images to dense correspondences of a human mesh model using deep networks
- DensePose is based on instance segmentation architectures and predicts body-wise UV maps for each pixel
- Shapovalov et al.’s work focused on lifting dense pose surface maps to 3D human models without 3D supervision
- Radar-based systems and WiFi are different
- mmMesh generates 3D human mesh from commercially portable millimeter-wave devices
- WiFi-based person localization using the traditional time-of-flight (ToF) method is limited
- Fei Wang et.al. demonstrated that it is possible to detect 17 2D body joints and perform 2D semantic body segmentation mask using only WiFi signals
- Our research aims to conduct dense pose estimation via WiFi
Methods
- Raw CSI signals are cleaned by amplitude and phase sanitization
- Two-branch encoder-decoder network performs domain translation from sanitized CSI samples to 2D feature maps
- 2D features are fed to a modified DensePose-RCNN architecture to estimate the UV map
- Transfer learning is used to minimize differences between feature maps produced by images and WiFi signals
- Raw CSI data is sampled in 100Hz with 30 subcarrier frequencies
- Inputs of network contain 5 consecutive CSI samples under 30 frequencies
- Outputs include 17 keypoint heatmaps and 25 UV maps
Phase sanitization
- Raw CSI samples are noisy and have random phase drift and flip.
- Most WiFi-based solutions rely only on the amplitude of CSI signals.
- Discarding phase information has a negative impact on performance.
- Sanitization is used to obtain stable phase values and enable full use of CSI information.
Modality translation network
- Modality Translation Network is used to transform network inputs from the CSI domain to the spatial domain
- Two encoders are used to extract CSI latent space features from the amplitude and phase tensors
- Each element of the tensors captures a unique 1D summary of the entire scene
- Fused 1D feature is reshaped into a 24x24 2D feature map
- Two convolution blocks are used to extract spatial information and obtain a 6x6 feature map
- Four deconvolution layers are used to upsample the encoded feature map to 3x720x1280
Wifi-densepose rcnn
- Obtain 3x720x1280 scene representation in image domain
- Utilize image-based methods to predict UV maps of human bodies
- Pose estimation algorithms are two-stage
- Not possible to extract signals corresponding to single person from group
- Adopt network structure similar to DensePose-RCNN
- Extract spatial features from 3x720x1280 imagelike feature map
- Network contains two branches: DensePose head and Keypoint head
- Estimate keypoint locations and densely predict human part labels and surface coordinates
- Output 17x56x56 keypoint mask and 25x112x112 IUV map
Transfer learning
- Training the Modality Translation Network and WiFi-DensePose RCNN network takes 80 hours
- Transfer learning is used to improve training efficiency
- Transfer learning involves a teacher and student network
- Mean squared error is used to calculate transfer learning loss
- Transfer learning results in higher performance and fewer iterations to converge
Losses
- Total loss is computed using 5 components
- Classification and box regression losses are standard RCNN losses
- DensePose loss consists of several sub-components
- Cross-entropy loss for coarse segmentation and body part classification
- Smooth L1 loss for UV coordinate regression
Experiments
- Experiment conducted to validate WiFi-based DensePose
- Results of experiment presented in this section
Dataset
- Dataset 1 contains CSI samples and videos taken at 100Hz and 20 FPS respectively.
- Dataset 1 was gathered in 16 spatial layouts with 1-5 subjects in each layout.
- Pre-trained models were used to produce pseudo ground truth.
- Pseudo ground truth includes person bounding boxes, segmentation masks, UV maps, and keypoint coordinates.
Training/testing protocols and metrics
- Two protocols are used to evaluate the performance of the algorithm: Same Layout and Different Layout
- The Same Layout protocol randomly selects 80% of the samples for training and the rest for testing
- The Different Layout protocol trains on 15 spatial layouts and tests on 1 unseen spatial layout
- The performance of the algorithm is evaluated in two aspects: the ability to detect humans and accuracy of the dense pose estimation
- Standard Average Precision (AP) is calculated for person bounding boxes at multiple IOU thresholds
- Geodesic Point Similarity (GPS) and Masked Geodesic Point Similarity (GPSm) are used to measure the performance of DensePose detection
Implementation details
- Implemented approach in PyTorch
- Training batch size of 16 on 4 GPU server
- Empirically set = 0.6, = 0.3, = 0.1
- Warmup multi-step learning rate scheduler
- Initial learning rate of 1 − 5
- Learning rate increases to 1 − 3 for first 2000 iterations
- Learning rate decreases to 1 10 of its value every 48000 iterations
- Trained for 145,000 iterations for final model
Wifi-based densepose under same layout
- WiFi-based DensePose under the Same Layout protocol had a high AP@50 (87.2) and a low AP@75 (35.6).
- DensePose estimations had high dpAP • GPS@50 and dpAP • GPSm@50, but low dpAP • GPS@75 and dpAP • GPSm@75.
Comparison with image-based densepose
- WiFi dataset does not have manual annotations, making it difficult to compare performance of WiFi-based DensePose with its Image-based counterpart
- Image-based DensePose baseline was used to compare performance
- Estimations from WiFi-based model are reasonably well compared to Image-based DensePose
- WiFi-based model has lower absolute metrics, but small difference between AP-m and AP-l values
Ablation study
- Incorporating phase information slightly improves performance
- Adding a keypoint branch increases performance significantly
- Transfer learning reduces training time without sacrificing performance
Performance in different layouts
- Results obtained using same layout for training and testing
- Performance decreases significantly when tested on unseen domain
- Image-based model suffers from same domain generalization problem
Failure cases
- WiFi-based model produces wrong body parts when body poses rarely seen in training set
- Difficult to extract detailed information for each individual when 3+ subjects in one capture
Conclusion and future work
- Demonstrated dense pose estimation from WiFi signals
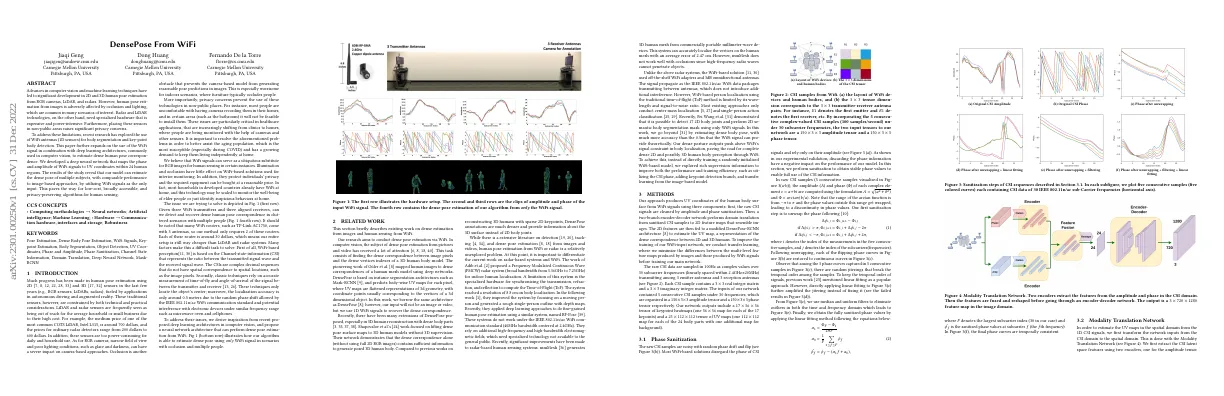
- Hardware setup illustrated in Figure 1
- CSI tensor of 3x3 dimensions
- 5 consecutive complex-valued CSI samples used
- Modality Translation Network used to extract features from amplitude and phase
- WiFi-DensePose RCNN used to extract person-wise features
- Transfer learning from image-based teacher network
- Performance limited by public training data
- Future work to collect multi-layout data and extend to 3D human body shapes
- Qualitative comparison of image-based and WiFi-based DensePose in Figures 9 and 10
- Ablation study of human detection and DensePose estimation
- Metrics used to measure performance