Link to paper
The full paper is available here.
You can also find the paper on PapersWithCode here.
Abstract
- Labeling systems have been proposed to help monitor work on the UN SDGs.
- Systems differ in their specificity and sensitivity and have systematic biases.
- An ensemble model that pools labeling systems can exceed the performance of all currently available systems.
Paper Content
Results
- Compare seven labeling systems on metrics and three labeled data sets
- Assess bias of different SDGs
- Assess susceptibility of labeling systems to produce false positives based on text length
- Assess potential of ensemble models to address limitations of individual labeling systems
Sdg labeling systems differ in their sensitivity-specificity trade-offs
- Compared seven labeling systems to generate predicted labels for documents from three labeled data sets
- Data sets differ in number of words per document and number of SDGs they were evaluated for
- Titles data set had 63% of documents judged to contain one SDG
- Abstracts data set had 80.2% of documents assigned an SDG
- News articles data set had 100% of documents assigned one or more SDGs
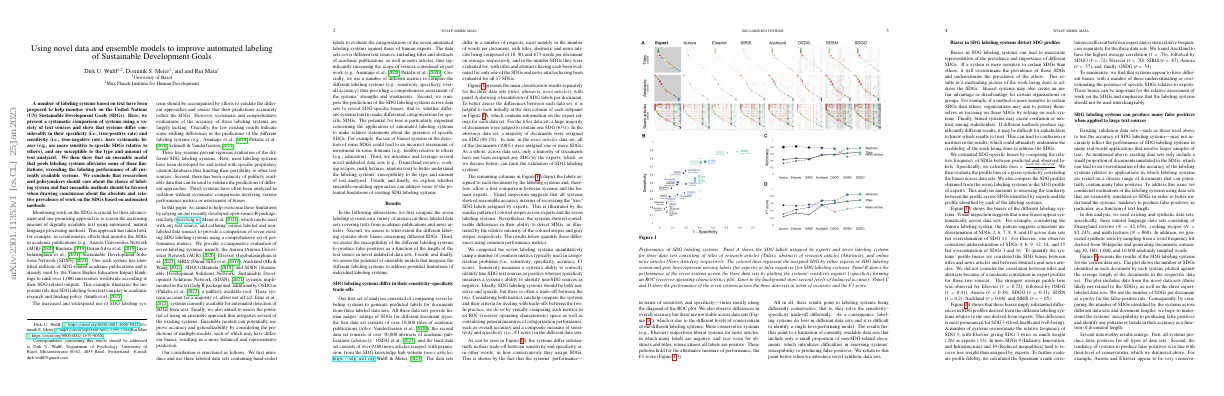
- Visual inspection suggests all systems showed reasonable accuracy in terms of recovering the “true” SDG labels assigned by experts
- Compared systems quantitatively using common metrics (sensitivity, specificity, accuracy, F1 score)
- Systems differ in trade-off between sensitivity and specificity
- Results point to labeling systems being differently conservative
- Difficult to identify single best-performing model
- Limitation of available data sets with small proportion of non-SDG-related documents
Biases in sdg labeling systems distort sdg profiles
- Biases in SDG labeling systems can lead to inaccurate representation of the prevalence and importance of different SDGs.
- Biased systems may create an unfair advantage or disadvantage for certain organizations or groups.
- Biased systems may create confusion or mistrust among stakeholders.
- We estimated SDG-specific biases by comparing the relative frequency of SDGs between predicted and observed labels.
- We found Auckland to have the highest average correlation, followed by SDGO, Elsevier, SIRIS, Aurora, and OSDG.
Sdg labeling systems can produce many false positives when applied to large text sources
- Existing validation data sets may not accurately reflect the performance of SDG labeling systems in real-world applications.
- Existing data sets only include a small proportion of documents unrelated to the SDGs, which can lead to an overestimation of accuracy.
- Evaluations of the labeling systems were conducted using existing and synthetic data sets.
- The tendency of systems to produce false positives is in line with their level of conservatism.
- The tendency to detect SDGs increases considerably when the length of the texts increases.
Trained ensemble models alleviate the shortcomings of existing labeling systems
- Existing SDG labeling systems have shortcomings
- Labeling systems differ in conservatism and accuracy
- False positives increase with document length
- Ensemble models of SDG labeling systems are trained using 6 publicly available labeling systems and document length
- Ensemble model achieves higher accuracy than individual labeling systems
- Ensemble model has even performance across data sets
- Profile bias and fidelity of ensemble model outperform individual systems
- Feature importance varies across SDGs
Discussion
- Aimed to compare existing automated labeling systems to identify work on SDGs from text
- Compared seven systems using various text sources and metrics
- Systems differ in accuracy and performance varies across text sources
- Systems have different biases that can impact overall profile of SDGs identified
- Reliance on automated systems for ranking institutions’ contributions to SDGs requires reliable systems
- Ensemble models can overcome limitations of individual labeling systems
- Ensemble models can achieve higher performance and less susceptible to biases
- Recommend use of ensemble approaches as best practice when drawing conclusions about SDGs based on automated methods
Methods
- Systems based on Lucene-style queries vary in complexity
- SDSN and OSDG systems are least complex, only use OR operations
- SIRIS and Elsevier systems are more complex, use AND operations
- Aurora system is most complex, uses NEAR operations
- Data sets used include Aurora, OSDG Community, SDG Knowledge Hub, Disneyland reviews, cooking recipes, math lectures, and synthetic data
- Algorithms used to train ensembles of SDG labeling systems are random forest and extreme gradient boosting
- Cases in data sets initially weighted by 1/N, synthetic data multiplied by factor k