Link to paper
The full paper is available here.
You can also find the paper on PapersWithCode here.
Abstract
- Pi3D dataset consists of 1000 planes observed in 10,000 images from 1DSfM dataset
- HEB dataset consists of 226,260 homographies and 4M correspondences
- Applications of Pi3D dataset include training/evaluating monocular depth, surface normal estimation and image matching algorithms
- HEB dataset used to evaluate robust estimators and deep learning-based correspondence filtering methods
Paper Content
Introduction
- Planar homography is a projective mapping between images of co-planar 3D points
- Homography encodes intrinsic and extrinsic camera parameters and parameters of the underlying 3D plane
- Homography plays an important role in multiple view geometry, calibration, metric rectification, augmented reality, optical flow, video stabilization, and Structure-from-Motion
- Traditional approach of finding homographies in image pairs consists of two stages: feature points detection and matching, and robust estimation
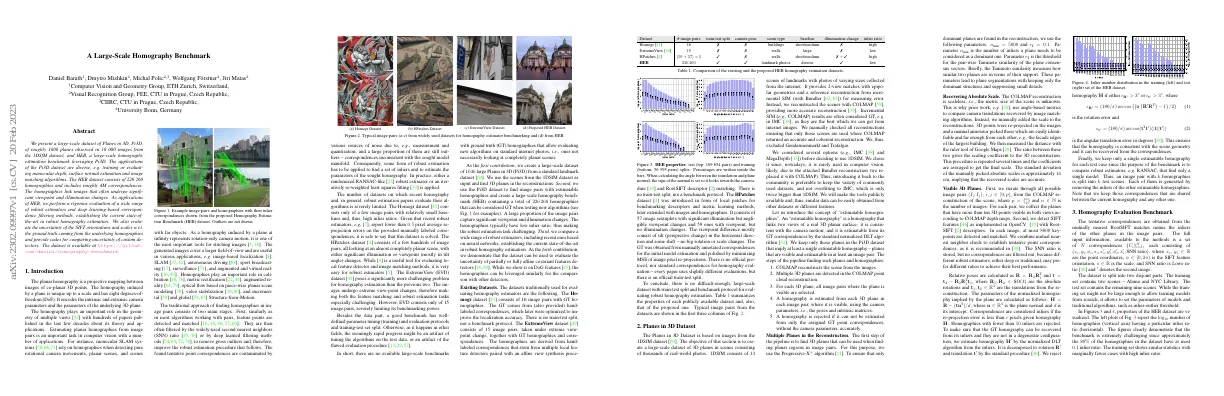
- Existing datasets for evaluating homography estimators are Homogr, ExtremeView, and HPatches
- Proposed dataset is Pi3D, consisting of 1046 large planes in 3D, and HEB, containing 226 260 homographies
- Dataset can be used to evaluate uncertainty of partially or fully affine covariant feature detectors
Planes in 3d dataset
- Dataset of 3D planes in scenes consisting of thousands of real-world photos
Homography evaluation benchmark
- Tentative correspondences are obtained from mutually nearest RootSIFT matches
- Input information is a set of N correspondences
- Dataset is split into two disjoint parts: training set (2 scenes) and test set (9 scenes)
- 80% of homographies have at most 0.1 inlier ratio
- Histograms of angle between translations and plane normals show all possible directions are well-covered
- 30% of homographies have fewer than 20 inliers
- Majority of homographies have fewer than 50 inliers
Experimental protocol
- Evaluation protocol largely influenced by Image Matching Benchmark
- Metrics include pose-based, ground truth correspondences-based, and self-supervised
- Main metric is mean average accuracy with thresholds
- Metrics comparison shows mostly agreement, with some exceptions
- Training and test protocols proposed for fair evaluation
- Hyper-parameters tuned on training set, then fixed for test set
- Methods for homography estimation include traditional algorithms, deep prefiltering
- Traditional algorithms include OpenCV RANSAC, LMEDS, LSQ, RHO, MAGSAC++, Graph-Cut RANSAC, scikit-image RANSAC, EAS, kornia-CPU
- Deep prefiltering uses pre-trained models for correspondence prefiltering
Experiments
- Traditional methods show the most accurate method is Affine GC-RANSAC
- PROSAC sampling improves results by up to 10 percentage points
- Optimized implementation matters for speed
- SNN ratio filtering reduces difference between methods
- RHO algorithm is fastest
- Affine GC-RANSAC benefits least from correspondence prefiltering
- LSQ fitting and LMEDS yield inaccurate results
- EAS algorithm leads to highly inaccurate results
- Deep prefiltering provides accuracy boost to advanced RANSACs
- OANet provides best results
- Vanilla OpenCV RANSAC with OANet or CLNet prefiltering performs similarly to VSAC + SNN ratio
- Uncertainty of SIFT keypoints is approx. 1/3 pixel
- STD of angular, scale, and positional transformations of detected correspondences is approx. 12°, 0.51, and 0.67 pixels respectively
Conclusion
- Pi3D and HEB datasets are presented
- Applications of the datasets are diverse, e.g. training or evaluating monocular depth, surface normal estimation and image matching algorithms
- VSAC and OANet achieve the top accuracy
- PROSAC accelerates RANSAC by an order of magnitude
- Exploiting SIFT orientation and scale has clear benefits in Affine GC-RANSAC
- Dataset, including reconstruction with absolute scale, and tools for adding new features will be made available
- Large number of homographies allows for analyzing noise in partially or fully affine-covariant features
- Evaluated DoG features
- Investigated actual noise in orientation and scaling components of such features
- Described components of each algorithm compared in main paper
- All tested methods use normalized direct linear transformation algorithm
- OpenCV RANSAC, LMEDS, LSQ, LO-RANSAC, LO-RANSAC+ with LAF, pydegensac, OpenCV GC-RANSAC and MAGSAC++, VSAC with PROSAC, RHO, CNe, ACNe, DFE, OANet, Neural Guiding, CLNet
- Evaluated bias and variance of angular, scale, and positional transformations of detected correspondences of SIFT keypoints
- Measured standard deviation for individual bins of symmetric positional residuals w.r.t. related scales
- Evaluated scale transformation accuracy and uncertainty