Link to paper
The full paper is available here.
You can also find the paper on PapersWithCode here.
Abstract
- Generative AI models have impressive performance on NLP tasks.
- Evaluating generative AI is challenging.
- MEGA is a benchmark for generative LLMs, covering 8 tasks and 33 languages.
- Comparing generative LLMs to SOTA non-autoregressive models.
- Analysis of performance across languages and directions for future progress.
Paper Content
Introduction
- Generative Large Language Models (LLMs) have created a lot of interest due to their capabilities
- LLMs have been tested on languages other than English with varying results
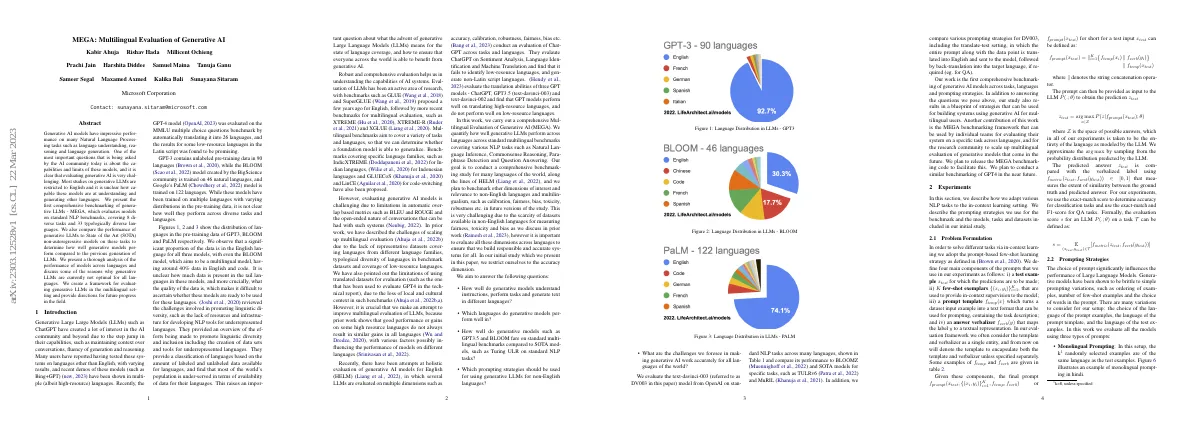
- GPT-4 model was evaluated on the MMLU multiple choice questions benchmark in 26 languages
- GPT-3, BLOOM and PaLM models have been trained on multiple languages
- It is unclear how well LLMs perform across diverse tasks and languages
- Most of the world’s population is under-served in terms of availability of data for their languages
- Evaluation of LLMs has been an active area of research with multiple benchmarks
- Challenges of scaling up multilingual evaluation due to lack of resources and infrastructure
- Limitations of using translated datasets for evaluation
- Holistic evaluation of generative AI models for English (HELM)
- Bang et al. (2023) evaluate ChatGPT across tasks and languages
- Hendy et al. (2023) evaluate translation abilities of three GPT models
- Comprehensive Multilingual Evaluation of Generative AI (MEGA) to quantify how well generative LLMs perform across languages
- Blueprint of strategies for building systems using generative AI for multilingual users
- MEGA benchmarking framework to evaluate systems on specific tasks across languages
Experiments
- Adapting NLP tasks to in-context learning setting
- Describing prompting strategies for benchmark
- Models, tasks and datasets included in initial study
Problem formulation
- Adopt prompt-based few-shot learning strategy
- Define four components of prompts: test example, few-shot exemplars, prompt template, answer verbalizer
- Prompt is composed of template and verbalizer
- Evaluation score is determined by exact-match and F1-score for QA tasks
Prompting strategies
- Choice of prompt affects performance of Large Language Models
- Generative models are sensitive to simple prompting variations
- Variations include language of prompt examples, language of prompt template, and language of test examples
- Monolingual prompting uses same language for k1 randomly selected examples and test examples
- Zero-Shot Cross-Lingual prompting uses k-shot examples from a pivot language different from language of test example
- Translate-Test prompting modifies test example by translating it to English
- English-Template uses English prompts for all experiments
- Native-Language-Template uses native language prompts, but performs poorly
Models
- Used OpenAI’s GPT text-davinci-003 model for benchmarking experiments
- Compared performance of DV003 with BLOOMZ, TULRv6 and MuRIL models
Tasks and datasets
- Two broad families of NLU tasks: Classification and Question Answering
- Performance of different models measured in terms of classification accuracy
- Exact match between generated output and verbalized label to determine if example was classified correctly
- Span Prediction type of Question Answering tasks
- Challenge of fitting context and question pairs into maximum context size of 4096
- Exact Match and F1 score used to measure performance
- Four tasks used for benchmarking: TyDiQA, MLQA, XQuAD, IndicQA
Few-shot examples
- Randomly chose few-shot examples from development set
- Better choices of few-shot examples can lead to higher performance
Choice of prompts
- Use PromptSource from BigScience community to create prompts for tasks
- Evaluate performance of English prompts on 10% of English test set
- Select best performing English prompt for entire test set
- Translate English prompt to target language using Bing translator
Results
- Analyzed the results of MEGA over each task in two parts
- Compared performance of best DV003 system to BLOOMZ, TULR and MuRIL
- Y axis ordered by language class according to Joshi et al. (2020)
- Class 5 corresponds to high resource languages, Class 1 and 2 are underresourced languages
- Included results on English for each task to show gap between performance in English and other languages
Comparison across prompting strategies
- Translatetest performs best across all languages
- Monolingual prompting works best for some languages
- Translatetest outperforms other settings by a large margin
- Performance is much worse for non-Latin script languages
Comparison across models
- DV003 compared to generative and SOTA non-autoregressive models
- TULRv6 outperforms other models
- BLOOMZ performs worse than DV003 translate-test, but better for some languages
- MuRIL model outperforms DV003 on all languages
- TULRv6 performs best for XCOPA, PAWS-X, TyDiQA and XQUAD
- TULRv6 outperforms DV003 in all languages, with higher gap in low-resource and non-Latin script languages
- Table 3 provides summary of results averaged over all languages
Discussion
- Translate-test setting works best for DV003 across all tasks
- Generative LLMs (DV003 and BLOOMZ) have lower performance than SOTA models
- Gap between generative LLMs and SOTA models is reduced for high-resource languages
- Gap is higher for under-resourced languages
Tokenization
- Tokenization is a key component that influences the performance of multilingual models
- Poor tokenization for some lower-resource languages can lead to poor context encapsulation and poor semantic representations of inputs
Translating prompts to multiple languages
- Translating prompts often results in semantically meaningless prompts for some moderate-resource languages.
- Human supervision or post-editing is necessary to generate meaningful prompts for such languages.
- Translation appears to favor languages which share scripts with higher-resource languages.
- Sharing dominant scripts leads to better cross-lingual transfer and improved performance on downstream tasks.
Translate-test
- Translate-test prompt setting works best overall for all languages and tasks.
- Translating into English and querying the system is feasible for languages supported by translators.
- Translation performance of M2M is presented in Table 4.
Looking forward
- Benchmarking generative AI models across languages
- Expand language coverage to include low-resource languages and typologically diverse languages
- Include more standard NLP tasks and tasks from real-world applications
- Compare against BLOOMZ and include more generative models such as GPT4
- Include other dimensions such as calibration, fairness, toxicity, bias and disinformation
- Incorporate datasets that represent multilingual communication, such as code-switching
Conclusion
- Generative LLMs perform worse than SOTA models
- Perform better on higher-resource languages and Latin script
- Tokenization in GPT may be a reason for the gap
- Choice of prompting strategy matters
- Tuning prompts is challenging to scale
- Need to scale up multilingual prompt generation
- Translate-test is currently the best strategy
- Prioritize automatic benchmarking and human evaluation
- Little representation from African and Indigenous languages
- Restricted to accuracy dimension of evaluation
- Figures 1-26 included in paper